Where to get data?¶
This page lists some source corpora and pre-trained word vectors you can download.
Source corpora¶
English Wikipedia, August 2013 dump, pre-processed
- One-sentence per line, cleaned from punctuation
- One-word-per-line, parser tokenization (this is the version used in the non-dependency-parsed embeddings downloadable below, so use this one if you would like to have directly comparable embeddings)
- Dependency-parsed version (CoreNLP Stanford parser)
Pre-trained VSMs¶
English
Wikipedia vectors (dump of August 2013)
Here you can download 500-dimensional pre-trained vectors for the popular CBOW, Skip-Gram and GloVe VSMs - each in 4 kinds of context:
These embeddings were generated for the following paper. Please cite it if you use them in your research:
@inproceedings{LiLiuEtAl_2017_Investigating_Different_Syntactic_Context_Types_and_Context_Representations_for_Learning_Word_Embeddings,
title = {Investigating {{Different Syntactic Context Types}} and {{Context Representations}} for {{Learning Word Embeddings}}},
url = {http://www.aclweb.org/anthology/D17-1256},
booktitle = {Proceedings of the 2017 {{Conference}} on {{Empirical Methods}} in {{Natural Language Processing}}},
author = {Li, Bofang and Liu, Tao and Zhao, Zhe and Tang, Buzhou and Drozd, Aleksandr and Rogers, Anna and Du, Xiaoyong},
year = {2017},
pages = {2411--2421}}
You can also download the source corpus (one-word-per-line format) with which you can train other VSMs for fair comparison.
Each of the 3 models (CBOW, GloVe and Skip-Gram) is available in 5 sizes (25, 50, 100, 250, and 500 dimensions) and in 4 types of context: the traditional word linear context (which is used the most often), the dependency-based structured context, and also less common structured linear and word dependency context.
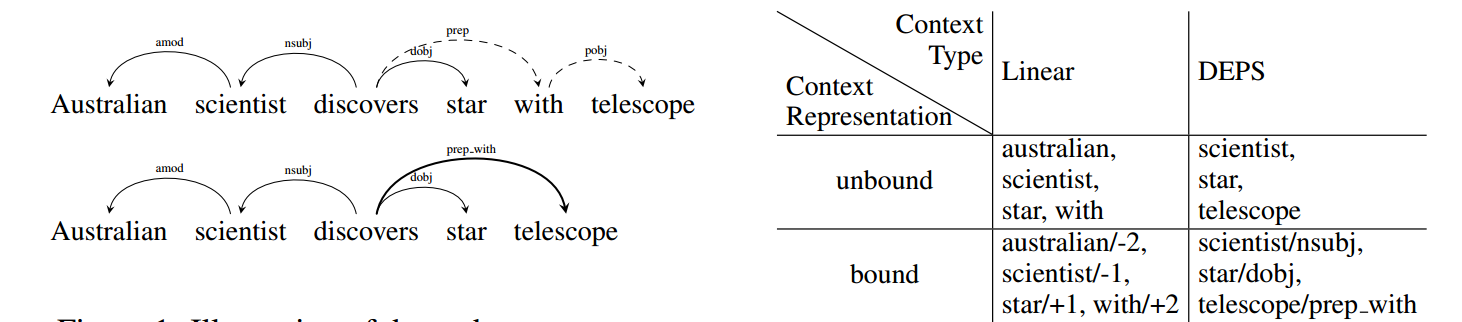
Unbound linear context (aka word linear context)
500 dimensions: word_linear_cbow_500d, word_linear_sg_500d, word_linear_glove_500d
250 dimensions: word_linear_cbow_250d, word_linear_sg_250d, word_linear_glove_250d
100 dimensions: word_linear_cbow_100d, word_linear_sg_100d, word_linear_glove_100d
50 dimensions: word_linear_cbow_50d, word_linear_sg_50d, word_linear_glove_50d
25 dimensions: word_linear_cbow_25d, word_linear_sg_25d, word_linear_glove_25d
Unbound dependency context (aka word dependency context)
500 dimensions: word_deps_CBOW_500d, word_deps_sg_500d, word_deps_glove_500d
250 dimensions: word_deps_cbow_250d, word_deps_sg_250d, word_deps_glove_250d
100 dimensions: word_deps_cbow_100d, word_deps_sg_100d, word_deps_glove_100d
50 dimensions: word_deps_cbow_50d, word_deps_sg_50d, word_deps_glove_50d
25 dimensions: word_deps_cbow_25d, word_deps_sg_25d, word_deps_glove_25d
Bound linear context (aka structured linear context)
500 dimensions: structured_linear_cbow_500d, structured_linear_sg_500d, structured_linear_glove_500d
250 dimensions: structured_linear_cbow_250d, structured_linear_sg_250d, structured_linear_glove_250d
100 dimensions: structured_linear_cbow_100d, structured_linear_sg_100d, structured_linear_glove_100d
50 dimensions: structured_linear_cbow_50d, structured_linear_sg_50d, structured_linear_glove_50d
25 dimensions: structured_linear_cbow_25d, structured_linear_sg_25d, structured_linear_glove_25d
Bound dependency context (aka structured dependency context)
500 dimensions: structured_deps_cbow_500d, structured_deps_sg_500d, structured_deps_glove_500d
250 dimensions: structured_deps_cbow_250d, structured_deps_sg_250d, structured_deps_glove_250d
100 dimensions: structured_deps_cbow_100d, structured_deps_sg_100d, structured_deps_glove_100d
50 dimensions: structured_deps_cbow_50d, structured_deps_sg_50d, structured_deps_glove_50d
25 dimensions: structured_deps_cbow_25d, structured_deps_sg_25d, structured_deps_glove_25d
The training parameters are as follows: window 2, negative sampling size is set to 5 for SG and 2 for CBOW. Distribution smoothing is set to 0.75. No dynamic context or “dirty” sub-sampling. The number of iterations is set to 2, 5 and 30 for SG, CBOW and GloVe respectively.
SVD vectors:
| BNC, 100M words: | |
|---|---|
| window 2, 500 dims, PMI; SVD C=0.6, 318 Mb, mirror | |
Russian
| Araneum+Wiki+Proza.ru, 6B words: | |
|---|---|
| window 2, 500 dims, PMI; SVD C=0.6, 2.3 Gb, mirror, paper to cite | |
@inproceedings{7396482,
author={A. Drozd and A. Gladkova and S. Matsuoka},
booktitle={2015 IEEE International Conference on Data Science and Data Intensive Systems},
title={Discovering Aspectual Classes of Russian Verbs in Untagged Large Corpora},
year={2015},
pages={61-68},
doi={10.1109/DSDIS.2015.30},
month={Dec}}